


Concept
Figure 1 shows an overview of the proposed total concept of the intended approach. There are already existing sensors of the internet analyzing systems to generate flow data, which are under iAID also expanded to include a hardware-supported version for broadband networks. These IAS flows are a statistical representation of the network packet header information of each packet, which was replaced as a TCP or UDP communication.
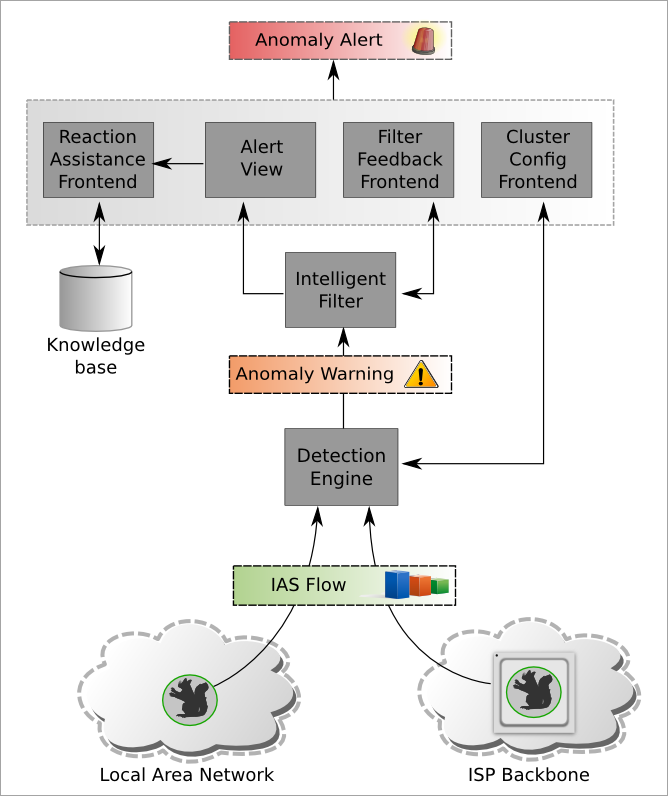
Figure 1: general survey of IAS flow data process
For the evaluation of the collected meta data in different formats (such as IAS flow or NetFlow), the detection engine framework can be extended to new procedures. These procedures are able to detect abnormal network flows based on network statistics. The stages of this detection process are shown schematically in Figure 2. These flows are classified first in a clustering process into different groups (clusters). This arrange could be conducted with the help of employed protocols on application layer. It is necessary to increase the accuracy of the abnormality detection. Would this not be done, the differences would statistically significantly outweigh between protocols than the differences between flows of same protocols. Clusters should already be arranged in three classes by the user, too:
- good-natured clusters: flows of these clusters are known as good-natured and they can be ignored in the following progress.
- neutral clusters: the actual anomaly detection takes place within these clusters.
- malicious clusters: flows of this category of clusters were generally classified as suspicious. There is no anomaly-detection and flows will automatically passed to the next processing stage.
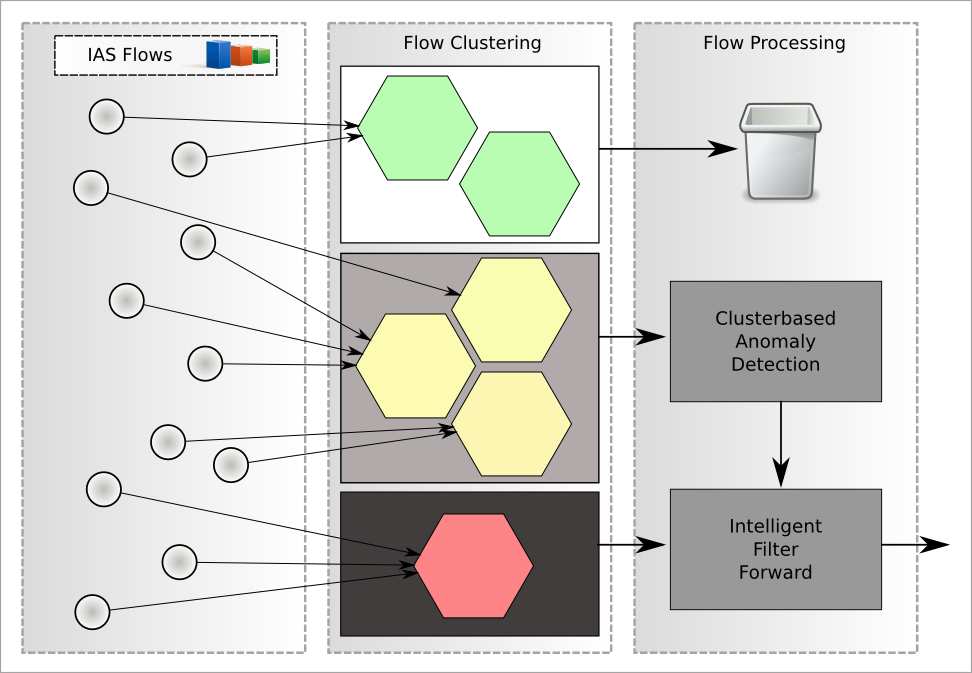
Figure 2: anomaly detection of IAS flow data
Anomalous flow data from neutral and malicious clusters are passed to an intelligent filter. This filter will passed all flows enriched with additional information to a user. If a flow will be identified as non-dangerous, in the future similar flows are also non-dangerous. This requires different methods and similarity measures which are evaluated for this. Necessary additional information to enable a decision, and a suitable representation has to be found. Additional information may be generally known or updated information about the ports should be found, for example. If dangerous flows will be discovered in the processing of alerts the system, they can also be explicitly selected to train the filter. In addition, the information can be extended to descriptions, which include countermeasures. From that a warning (alarm) can be generated. This warning must be subsequently processed by a security expert.
The following scientific key issues arising from the proposed process:
- clustering: which clustering methods are used to divide into groups to flow data, in which a sensible anomaly detection might be possible?
- anomaly detection: which methods and models are the best to identify
statistic anomaly network flows by flow data.
- Is it possible to reduce an amount of a flow method of feature selection to make the process more performant or more precisely?
- What is the probability of network flows that are statistically abnormal or indeed described as a threat?
- intelligent filter: proximities which will be used for clustering and anomaly detection, are also used for intelligent filtering or other necessary approaches?